Come si realizza l'architettura di un sito web scalabile?
Un sito web può essere realizzato in mille modi diversi, tutti validi ed ugualmente funzionanti. Vediamo insieme un'architettura di base, che potrebbe aiutarvi a ragionare su quali sono i sistemi che vengono impattati nella realizzazione di un sistema scalabile.
Premessa
Per sua natura, Internet è un "BLOB" che si evolve giornalmente, un mondo nel quale ogni giorno nasce un nuovo prodotto. Se ieri un prodotto era il leader di mercato, oggi potrebbe essere abbandonato perché superato da qualcosa di nuovo.
Questo si riflette anche sulle architetture web: progettare un sito web in grado di evolvere e scalare, assorbendo oggi 1.000 utenti e domani 100.000, può essere fatto in molti modi diversi e puntualmente, al termine della sua progettazione, ci si potrebbe accorgere che qualcosa poteva essere fatto in modo diverso.
Nel corso degli anni ho avuto la fortuna di progettare parecchie architetture web, di sbagliare e di migliorare e di sperimentare soluzioni completamente diverse fra di loro.
Di certi prodotti mi sono innamorato e non potrei mai farne a meno. è come andare in bicicletta: li installi e sai che ti risolveranno un problema, anche se sono stati superati tecnologicamente da altri, anche se forse fanno troppo rispetto a quello che ti serve.
Per altri prodotti invece non c'è un vero amore: occorre usarli perché il cliente vuole così o perché in quell'azienda non è possibile introdurre un prodotto diverso rispetto a quelli certificati o a quelli di cui si ha l'assistenza.
Costruiamo la nostra prima architettura
Prima di pensare al linguaggio di programmazione col quale andrò a sviluppare un progetto, mi faccio sempre delle domande rispetto a quanto traffico potrà ricevere durante il giorno o in un momento di picco.
Per fare questo utilizzo una semplice regola: dato 100 il numero di utenti previsti in un giorno, l'ora di picco dovrebbe assestarsi sul 10% del traffico totale.
Questa regola non è perfetta, ma in molti casi è andata vicina al reale traffico generato dal sito.
Riuscire a quantificare questo valore, anche in modo approssimato o tramite un valore "desiderato", permette di capire subito quanti strati software/macchine andranno aggiunte alla soluzione per poter scalare senza problemi e per raggiungere il traffico desiderato.
Un'altra domanda che mi faccio è: quanto si è disposti ad investire su questo progetto? Non spendere in risorse hardware limita molto il margine di lavoro di un progettista, quindi è un aspetto da considerare.
Una volta che penso di avere le risposte a queste domande, inizio a preparare uno schema di base di quella che potrebbe essere l'architettura di partenza.
Ricordiamoci sempre però che qualsiasi architettura è perfettibile, modificabile, adattabile o criticabile, dato che si basa sia sulle esigenze dei propri clienti che sulla propria esperienza di progetti software.
Frontend
Ci sono due parti fondamentali di cui occorre tener conto quando si realizza un'architettura: la parte di presentazione dei dati, che è quella che tutti vediamo quando navighiamo un sito internet, e la parte di business logic, che non vediamo ma percepiamo in base a quanto un sito risponde velocemente e correttamente.
In questo primo post vorrei soffermarmi sulla prima parte, sul frontend del sito, e di come realizzarlo in modo che possa facilmente essere modificato con l'aumentare del numero di utenti.
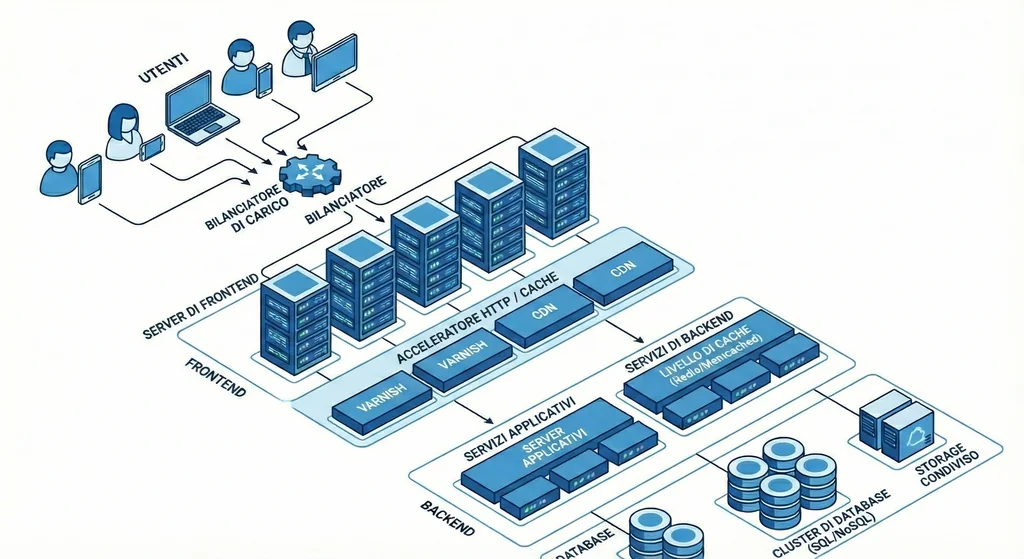
Proviamo quindi a partire con uno schema generico:

Scalabilità e cache
Uno degli approcci più utilizzati quando si realizza un sito web è quello di utilizzare uno "stack" standard.
Gli stack più famosi sono composti da sistema operativo, web server, database SQL e linguaggio di programmazione. Eccone alcuni esempi:
- LAMP: Linux, Apache, MySQL (o MariaDB), PHP (o Perl o Python)
- WAMP: Windows, Apache, MySQL (o MariaDB), PHP (o Perl o Python)
A prescindere dal tipo di stack scelto, architetture di questo genere vanno benissimo quando gli utenti concorrenti sono pochi. Quando la concorrenza aumenta di molto, si iniziano ad avere i primi problemi:
- Lentezza nella risposta dell'applicazione
- Raggiungimento del limite di utenti paralleli gestibili
- Problemi di memoria
In questi casi, il primo componente che si tende a installare, anche per il fatto che risulta abbastanza trasparente al sistema, è un bilanciatore di carico.
Bilanciatore
Lo scopo del bilanciatore è quello di prendere in carico le chiamate HTTP e decidere quale server, fra quelli in grado di indirizzare, andrà a gestire le richieste. Il suo compito è quindi abbastanza semplice e, non dovendo fare particolari elaborazioni se non discriminare il server da utilizzare, estremamente efficiente.
Negli anni ho provato vari bilanciatori, ma quello che ha dimostrato la maggior flessibilità è stato sicuramente HAProxy: performante, opensource e con un numero tale di opzioni da soddisfare anche i clienti più esigenti.
HTTP Accelerator
Al netto del fatto che un traffico bilanciato su più server è, da solo, in grado di fornire un traffico maggiore, esiste anche il problema che, in certi casi, la richiesta di alcune pagine ad un web server potrebbe risultare lenta.
I motivi di una lentezza sono molteplici:
- Errori logici di programmazione
- Servizi di backend lenti o posti "lontano" dalla parte di frontend
- Saturazione del servizio utilizzato, con conseguente accodamento delle chiamate
In questi casi, soprattutto quando a parità di chiamata la risposta è sempre uguale, è possibile introdurre dei meccanismi in grado di mettersi fra la chiamata e il web server, capire che viene chiesta una elaborazione fatta precedentemente (magari anche da un altro utente) e restituire lo stesso dato, evitando costose elaborazioni.
Un paio di prodotti in grado di fare questo lavoro sono:
- EHCache web: un filtro, da installare all'interno di applicativi Java, in grado di mantenere in memoria una copia delle pagine in modo del tutto trasparente.
- Varnish cache: un vero e proprio server di cache. In questo caso l'applicazione non viene toccata, viene eseguito il server Varnish di fronte al web server dell'applicazione. La chiamata arriva sempre a Varnish, che andrà poi a discriminare il fatto che debba essere o meno passata al web server.
Divisione dei contenuti
Quando progettate un'applicazione, uno dei punti che andrebbero controllati con attenzione è quello della distribuzione delle risorse: se una risorsa non muta nel tempo (per esempio uno script, un foglio di stile, una libreria, una immagine e così via) è buona norma indirizzarla su un dominio che esalti le capacità di cache del browser utilizzato e, contemporaneamente, ottimizzi la quantità di dati inviati tramite ottimizzazione e compressione dei dati.
Una delle tecniche maggiormente utilizzate in questi casi è quella di porre le risorse "largamente note" all'interno di servizi di CDN, in grado di soddisfare i requisiti di cui abbiamo parlato e scaricare il web server di inutili gestioni ripetitive.
Anche in questo caso è possibile realizzare il servizio in casa, utilizzando apposite configurazioni di Apache o Nginx, modificate rispetto ai default presenti al momento dell'installazione.
Responsive / Mobile friendly
Le tecniche di cui abbiamo parlato fino ad adesso vanno bene sia nel caso che l'applicazione sia da progettare da zero, sia che sia stata precedentemente progettata e debba solamente essere accelerata.
Se però dobbiamo progettare qualcosa di nuovo è importante tener conto anche di alcuni aspetti che prescindono lo stile grafico adottato. Nei nuovi progetti consiglio infatti di adottare sempre un approccio responsive.
Questo tipo di approccio ci permette da un lato di avere un progetto in grado di adattarsi egregiamente a qualsiasi risoluzione video, da un altro di non essere costretti ad avere un'app per navigare il sito in maniera decente.
Per riuscire ad avere un progetto responsive ci sono molte soluzioni opensource in rete. Per la maggiore vanno librerie come Bootstrap o Foundation che, seguendo le loro linee guida, permettono di avere velocemente una grafica responsive. Col tempo però molti programmatori hanno iniziato a prendere la mano sulle media query, in modo da poter gestire autonomamente dei layout responsive senza l'utilizzo di librerie esterne.
SEO
Una piccola nota deve essere fatta anche verso il SEO. Una progettazione che si rispetti deve tenere conto anche di questo aspetto, non tanto rispetto ai classici parametri di cui tutti i SEO parlano (meta tag title, description, h1, url rewrite etc), quanto alle nuove impostazioni rispetto ai meta tag dei social network come Facebook e Twitter e ai dati strutturati definiti Schema.org.
Avere un sito web ricco di informazioni, ma completamente destrutturate, è un vero peccato, in quanto non sfrutta a pieno il proprio potenziale.
Cache verso il backend
Ogni operazione che parte da un layer e arriva ad un altro costa tempo di elaborazione. Se il layer è fisicamente su un'altra macchina, magari in un'altra rete, c'è anche un problema di latenza delle informazioni.
Per questa ragione è importante pensare anche a un sistema di cache che, una volta che la chiamata HTTP è presa in carico dal frontend, possa frapporsi prima della chiamata al backend.
Questi sistemi di cache hanno normalmente dei protocolli di comunicazione proprietari e tendono a contenere in RAM il maggior numero di informazioni possibili, in modo da ridurre l'accesso ai dischi, decisamente più lenti che l'accesso a una RAM.
Anche in questo caso i prodotti sono innumerevoli, ma vorrei citarne almeno un paio in grado di gestire una cache di tipo key-value (chiave-valore):
Evoluzioni
Per non rendere l'articolo troppo lungo non mi sono soffermato su una serie di ottimizzazioni legati all'uso della cache lato browser. è infatti possibile ridurre le chiamate del browser verso il sito web semplicemente informandolo sulla durata della cache dei vari elementi che debbono essere scaricati durante la navigazione.
Allo stesso modo possiamo rendere asincrone le gestioni di alcuni elementi delle pagine, come script o immagini, in modo da caricarli solo nel momento di reale utilizzo: immaginate uno slideshow di 100 immagini e la differenza di prestazioni nel caricarle tutte insieme o solamente quando l'utente le visualizza a video.
Conclusioni
In questo primo articolo ho puntato l'attenzione sulla parte di frontend. Nelle prossime puntate andrò a concentrarmi maggiormente sui problemi legati al backend, dove elaborazione e gestione dati la fanno da padrone.
Mi rendo conto di aver solamente introdotto l'argomento architettura web, ma allo stesso tempo spero di aver suscitato l'interesse di qualche lettore verso gli argomenti trattati.